Created outputs¶
Several output files are created when tests are executed, and all of them are somehow related to test results. This section discusses what outputs are created, how to configure where they are created, and how to fine-tune their contents.
Different output files¶
This section explains what different output files can be created and
how to configure where they are created. Output files are configured
using command line options, which get the path to the output file in
question as an argument. A special value NONE
(case-insensitive) can be used to disable creating a certain output
file.
Output directory¶
All output files can be set using an absolute path, in which case they
are created to the specified place, but in other cases, the path is
considered relative to the output directory. The default output
directory is the directory where the execution is started from, but it
can be altered with the --outputdir (-d) option. The path
set with this option is, again, relative to the execution directory,
but can naturally be given also as an absolute path. Regardless of how
a path to an individual output file is obtained, its parent directory
is created automatically, if it does not exist already.
Output file¶
Output files contain all the test execution results in machine readable XML format. Log file , Report file and XUnit compatible result file files are typically generated based on them, and they can also be combined and otherwise post-processed with Post-processing outputs.
ちなみに
Starting from Robot Framework 2.8, generating Report file and XUnit compatible result file files as part of test execution does not anymore require processing output files. Disabling Log file generation when running tests can thus save memory.
The command line option --output (-o) determines the path where
the output file is created relative to the output directory. The default
name for the output file, when tests are run, is output.xml.
When Post-processing outputs with Rebot, new output files are not created
unless the --output option is explicitly used.
It is possible to disable creation of the output file when running tests by
giving a special value NONE to the --output option. Prior to Robot
Framework 2.8 this also automatically disabled creating log and report files,
but nowadays that is not done anymore. If no outputs are needed, they should
all be explicitly disabled using --output NONE --report NONE --log NONE.
Log file¶
Log files contain details about the executed test cases in HTML format. They have a hierarchical structure showing test suite, test case and keyword details. Log files are needed nearly every time when test results are to be investigated in detail. Even though log files also have statistics, reports are better for getting an higher-level overview.
The command line option --log (-l) determines where log
files are created. Unless the special value NONE is used,
log files are always created and their default name is
log.html.
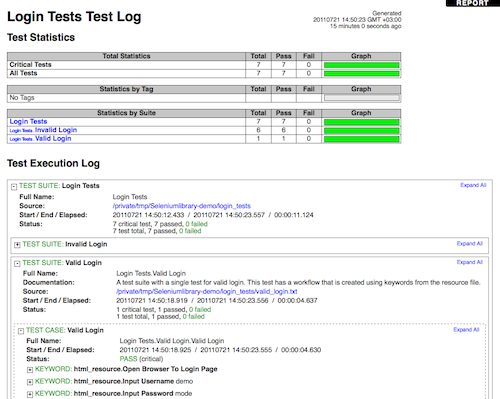
An example of beginning of a log file
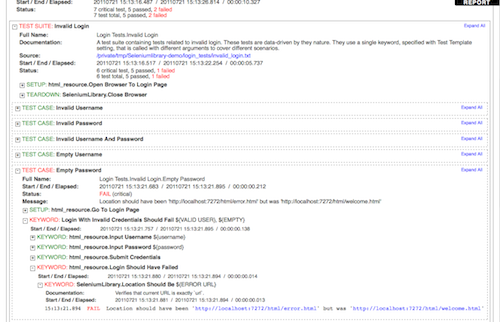
An example of a log file with keyword details visible
Report file¶
Report files contain an overview of the test execution results in HTML format. They have statistics based on tags and executed test suites, as well as a list of all executed test cases. When both reports and logs are generated, the report has links to the log file for easy navigation to more detailed information. It is easy to see the overall test execution status from report, because its background color is green, if all Setting criticality pass, and bright red otherwise.
The command line option --report (-r) determines where
report files are created. Similarly as log files, reports are always
created unless NONE is used as a value, and their default
name is report.html.

An example report file of successful test execution

An example report file of failed test execution
XUnit compatible result file¶
XUnit result files contain the test execution summary in xUnit compatible XML format. These files can thus be used as an input for external tools that understand xUnit reports. For example, Jenkins continuous integration server supports generating statistics based on xUnit compatible results.
ちなみに
Jenkins also has a separate Robot Framework plugin.
XUnit output files are not created unless the command line option
--xunit (-x) is used explicitly. This option requires a path to
the generated xUnit file, relatively to the output directory, as a value.
Because xUnit reports do not have the concept of `non-critical tests`__,
all tests in an xUnit report will be marked either passed or failed, with no
distinction between critical and non-critical tests. If this is a problem,
--xunitskipnoncritical option can be used to mark non-critical tests
as skipped. Skipped tests will get a message containing the actual status and
possible message of the test case in a format like FAIL: Error message.
注釈
--xunitskipnoncritical is a new option in Robot Framework 2.8.
Debug file Debug file ~~~~~~~~~~
Debug files are plain text files that are written during the test
execution. All messages got from test libraries are written to them,
as well as information about started and ended test suites, test cases
and keywords. Debug files can be used for monitoring the test
execution. This can be done using, for example, a separate
fileviewer.py
tool, or in UNIX-like systems, simply with the tail -f command.
Debug files are not created unless the command line option
--debugfile (-b) is used explicitly.
Timestamping output files¶
All output files listed in this section can be automatically timestamped
with the option --timestampoutputs (-T). When this option is used,
a timestamp in the format YYYYMMDD-hhmmss is placed between
the extension and the base name of each file. The example below would,
for example, create such output files as
output-20080604-163225.xml and mylog-20080604-163225.html:
robot --timestampoutputs --log mylog.html --report NONE tests.robot
Setting titles¶
The default titles for logs and reports are generated by prefixing
the name of the top-level test suite with Test Log or
Test Report. Custom titles can be given from the command line
using the options --logtitle and --reporttitle,
respectively. Underscores in the given titles are converted to spaces
automatically.
Example:
robot --logtitle Smoke_Test_Log --reporttitle Smoke_Test_Report --include smoke my_tests/
Setting background colors¶
By default the Report file has a green background when all the Setting criticality pass and a red background otherwise. These colors can be customized by using the --reportbackground command line option, which takes two or three colors separated with a colon as an argument:
--reportbackground blue:red
--reportbackground green:yellow:red
--reportbackground #00E:#E00
If you specify two colors, the first one will be used instead of the default green color and the second instead of the default red. This allows, for example, using blue instead of green to make backgrounds easier to separate for color blind people.
If you specify three colors, the first one will be used when all the test succeed, the second when only non-critical tests have failed, and the last when there are critical failures. This feature thus allows using a separate background color, for example yellow, when non-critical tests have failed.
The specified colors are used as a value for the body
element's background CSS property. The value is used as-is and
can be a HTML color name (e.g. red), a hexadecimal value
(e.g. #f00 or #ff0000), or an RGB value
(e.g. rgb(255,0,0)). The default green and red colors are
specified using hexadecimal values #9e9 and #f66,
respectively.
Log levels¶
Available log levels¶
Messages in log files can have different log levels. Some of the messages are written by Robot Framework itself, but also executed keywords can `log information`__ using different levels. The available log levels are:
FAIL- Used when a keyword fails. Can be used only by Robot Framework itself.
WARN- Used to display warnings. They shown also in `the console and in the Test Execution Errors section in log files`__, but they do not affect the test case status.
INFO- The default level for normal messages. By default, messages below this level are not shown in the log file.
DEBUG- Used for debugging purposes. Useful, for example, for logging what libraries are doing internally. When a keyword fails, a traceback showing where in the code the failure occurred is logged using this level automatically.
TRACE- More detailed debugging level. The keyword arguments and return values are automatically logged using this level.
Setting log level¶
By default, log messages below the INFO level are not logged, but this
threshold can be changed from the command line using the
--loglevel (-L) option. This option takes any of the
available log levels as an argument, and that level becomes the new
threshold level. A special value NONE can also be used to
disable logging altogether.
It is possible to use the --loglevel option also when
Post-processing outputs with Rebot. This allows, for example,
running tests initially with the TRACE level, and generating smaller
log files for normal viewing later with the INFO level. By default
all the messages included during execution will be included also with
Rebot. Messages ignored during the execution cannot be recovered.
Another possibility to change the log level is using the BuiltIn
keyword Set Log Level in the test data. It takes the same
arguments as the --loglevel option, and it also returns the
old level so that it can be restored later, for example, in a
テストのセットアップとティアダウン.
Visible log level¶
Starting from Robot Framework 2.7.2, if the log file contains messages at
DEBUG or TRACE levels, a visible log level drop down is shown
in the upper right corner. This allows users to remove messages below chosen
level from the view. This can be useful especially when running test at
TRACE level.

An example log showing the visible log level drop down
By default the drop down will be set at the lowest level in the log file, so
that all messages are shown. The default visible log level can be changed using
--loglevel option by giving the default after the normal log level
separated by a colon:
--loglevel DEBUG:INFO
In the above example, tests are run using level DEBUG, but
the default visible level in the log file is INFO.
Splitting logs¶
Normally the log file is just a single HTML file. When the amount of he test
cases increases, the size of the file can grow so large that opening it into
a browser is inconvenient or even impossible. Hence, it is possible to use
the --splitlog option to split parts of the log into external files
that are loaded transparently into the browser when needed.
The main benefit of splitting logs is that individual log parts are so small that opening and browsing the log file is possible even if the amount of the test data is very large. A small drawback is that the overall size taken by the log file increases.
Technically the test data related to each test case is saved into a JavaScript file in the same folder as the main log file. These files have names such as log-42.js where log is the base name of the main log file and 42 is an incremented index.
注釈
When copying the log files, you need to copy also all the log-*.js files or some information will be missing.
Configuring statistics¶
There are several command line options that can be used to configure and adjust the contents of the Statistics by Tag, Statistics by Suite and Test Details by Tag tables in different output files. All these options work both when executing test cases and when post-processing outputs.
Configuring displayed suite statistics¶
When a deeper suite structure is executed, showing all the test suite
levels in the Statistics by Suite table may make the table
somewhat difficult to read. By default all suites are shown, but you can
control this with the command line option --suitestatlevel which
takes the level of suites to show as an argument:
--suitestatlevel 3
Including and excluding tag statistics¶
When many tags are used, the Statistics by Tag table can become
quite congested. If this happens, the command line options
--tagstatinclude and --tagstatexclude can be
used to select which tags to display, similarly as
--include and --exclude are used to `select test
cases`__:
--tagstatinclude some-tag --tagstatinclude another-tag
--tagstatexclude owner-*
--tagstatinclude prefix-* --tagstatexclude prefix-13
Generating combined tag statistics¶
The command line option --tagstatcombine can be used to
generate aggregate tags that combine statistics from multiple
tags. The combined tags are specified using Tag patterns where
* and ? are supported as wildcards and AND,
OR and NOT operators can be used for combining
individual tags or patterns together.
The following examples illustrate creating combined tag statistics using different patterns, and the figure below shows a snippet of the resulting Statistics by Tag table:
--tagstatcombine owner-*
--tagstatcombine smokeANDmytag
--tagstatcombine smokeNOTowner-janne*

Examples of combined tag statistics
As the above example illustrates, the name of the added combined statistic
is, by default, just the given pattern. If this is not good enough, it
is possible to give a custom name after the pattern by separating them
with a colon (:). Possible underscores in the name are converted
to spaces:
--tagstatcombine prio1ORprio2:High_priority_tests
Creating links from tag names¶
You can add external links to the Statistics by Tag table by
using the command line option --tagstatlink. Arguments to this
option are given in the format tag:link:name, where tag
specifies the tags to assign the link to, link is the link to
be created, and name is the name to give to the link.
tag may be a single tag, but more commonly a Simple patterns
where * matches anything and ? matches any single
character. When tag is a pattern, the matches to wildcards may
be used in link and title with the syntax %N,
where "N" is the index of the match starting from 1.
The following examples illustrate the usage of this option, and the figure below shows a snippet of the resulting Statistics by Tag table when example test data is executed with these options:
--tagstatlink mytag:http://www.google.com:Google
--tagstatlink jython-bug-*:http://bugs.jython.org/issue_%1:Jython-bugs
--tagstatlink owner-*:mailto:%1@domain.com?subject=Acceptance_Tests:Send_Mail

Examples of links from tag names
Adding documentation to tags¶
Tags can be given a documentation with the command line option
--tagdoc, which takes an argument in the format
tag:doc. tag is the name of the tag to assign the
documentation to, and it can also be a Simple patterns matching
multiple tags. doc is the assigned documentation. Underscores
in the documentation are automatically converted to spaces and it
can also contain Documentation formatting.
The given documentation is shown with matching tags in the Test Details by Tag table, and as a tool tip for these tags in the Statistics by Tag table. If one tag gets multiple documentations, they are combined together and separated with an ampersand.
Examples:
--tagdoc mytag:My_documentation
--tagdoc regression:*See*_http://info.html
--tagdoc owner-*:Original_author
Removing and flattening keywords¶
Most of the content of Output file comes from keywords and their log messages. When creating higher level reports, log files are not necessarily needed at all, and in that case keywords and their messages just take space unnecessarily. Log files themselves can also grow overly large, especially if they contain for ループ or other constructs that repeat certain keywords multiple times.
In these situations, command line options --removekeywords and
--flattenkeywords can be used to dispose or flatten unnecessary keywords.
They can be used both when テストケースの実行 and when post-processing
:ref:`outputs. When used during execution, they only affect the log file, not
the XML output file. With rebot they affect both logs and possibly
generated new output XML files.
Removing keywords¶
The --removekeywords option removes keywords and their messages
altogether. It has the following modes of operation, and it can be used
multiple times to enable multiple modes. Keywords that contain errors or warnings are not removed except when using the ALL mode.
ALL- Remove data from all keywords unconditionally.
PASSED- Remove keyword data from passed test cases. In most cases, log files created using this option contain enough information to investigate possible failures.
FOR- Remove all passed iterations from for ループ except the last one.
WUKS- Remove all failing keywords inside BuiltIn keyword Wait Until Keyword Succeeds except the last one.
NAME:<pattern>- Remove data from all keywords matching the given pattern regardless the
keyword status. The pattern is
matched against the full name of the keyword, prefixed with
the possible library or resource file name. The pattern is case, space, and
underscore insensitive, and it supports Simple patterns with
*and?as wildcards. TAG:<pattern>- Remove data from keywords with tags that match the given pattern. Tags are
case and space insensitive and they can be specified using Tag patterns
where
*and?are supported as wildcards andAND,ORandNOToperators can be used for combining individual tags or patterns together. Can be used both with library keyword tags and ユーザキーワードのタグ.
Examples:
rebot --removekeywords all --output removed.xml output.xml
robot --removekeywords passed --removekeywords for tests.robot
robot --removekeywords name:HugeKeyword --removekeywords name:resource.* tests.robot
robot --removekeywords tag:huge tests.robot
Removing keywords is done after parsing the Output file and generating an internal model based on it. Thus it does not reduce memory usage as much as flattening keywords.
注釈
The support for using --removekeywords when executing tests
as well as FOR and WUKS modes were added in Robot
Framework 2.7.
注釈
NAME:<pattern> mode was added in Robot Framework 2.8.2 and
TAG:<pattern> in 2.9.
Flattening keywords¶
The --flattenkeywords option flattens matching keywords. In practice
this means that matching keywords get all log messages from their child
keywords, recursively, and child keywords are discarded otherwise. Flattening
supports the following modes:
FOR- Flatten for ループ fully.
FORITEM- Flatten individual for loop iterations.
NAME:<pattern>- Flatten keywords matching the given pattern. Pattern matching rules are
same as when removing keywords using
NAME:<pattern>mode. TAG:<pattern>- Flatten keywords with tags matching the given pattern. Pattern matching
rules are same as when removing keywords using
TAG:<pattern>mode.
Examples:
robot --flattenkeywords name:HugeKeyword --flattenkeywords name:resource.* tests.robot
rebot --flattenkeywords foritem --output flattened.xml original.xml
Flattening keywords is done already when the output file is parsed initially. This can save a significant amount of memory especially with deeply nested keyword structures.
注釈
Flattening keywords is a new feature in Robot Framework 2.8.2, FOR
and FORITEM modes were added in 2.8.5 and TAG:<pattern> in 2.9.
Setting start and end time of execution¶
When combining outputs using Rebot, it is possible to set the start
and end time of the combined test suite using the options --starttime
and --endtime, respectively. This is convenient, because by default,
combined suites do not have these values. When both the start and end time are
given, the elapsed time is also calculated based on them. Otherwise the elapsed
time is got by adding the elapsed times of the child test suites together.
It is also possible to use the above mentioned options to set start and end times for a single suite when using Rebot. Using these options with a single output always affects the elapsed time of the suite.
Times must be given as timestamps in the format YYYY-MM-DD
hh:mm:ss.mil, where all separators are optional and the parts from
milliseconds to hours can be omitted. For example, 2008-06-11
17:59:20.495 is equivalent both to 20080611-175920.495 and
20080611175920495, and also mere 20080611 would work.
Examples:
rebot --starttime 20080611-17:59:20.495 output1.xml output2.xml
rebot --starttime 20080611-175920 --endtime 20080611-180242 *.xml
rebot --starttime 20110302-1317 --endtime 20110302-11418 myoutput.xml
Programmatic modification of results¶
If the provided built-in features to modify results are are not enough,
Robot Framework 2.9 and newer provide a possible to do custom modifications
programmatically. This is accomplished by creating a model modifier and
activating it using the --prerebotmodifier option.
This functionality works nearly exactly like programmatic modification of test data that can be enabled with the --prerunmodifier option.
The obvious difference is that this time modifiers operate with the
result model, not the running model. For example, the following modifier
marks all passed tests that have taken more time than allowed as failed:
from robot.api import SuiteVisitor
class ExecutionTimeChecker(SuiteVisitor):
def __init__(self, max_seconds):
self.max_milliseconds = float(max_seconds) * 1000
def visit_test(self, test):
if test.status == 'PASS' and test.elapsedtime > self.max_milliseconds:
test.status = 'FAIL'
test.message = 'Test execution took too long.'
If the above modifier would be in file ExecutionTimeChecker.py, it could be used, for example, like this:
# Specify modifier as a path when running tests. Maximum time is 42 seconds.
robot --prerebotmodifier path/to/ExecutionTimeChecker.py:42 tests.robot
# Specify modifier as a name when using Rebot. Maximum time is 3.14 seconds.
# ExecutionTimeChecker.py must be in the module search path.
rebot --prerebotmodifier ExecutionTimeChecker:3.14 output.xml
If more than one model modifier is needed, they can be specified by using
the --prerebotmodifier option multiple times. When executing tests,
it is possible to use --prerunmodifier and
--prerebotmodifier options together.
System log¶
Robot Framework has its own plain-text system log where it writes information about
- Processed and skipped test data files
- Imported test libraries, resource files and variable files
- Executed test suites and test cases
- Created outputs
Normally users never need this information, but it can be
useful when investigating problems with test libraries or Robot Framework
itself. A system log is not created by default, but it can be enabled
by setting the environment variable ROBOT_SYSLOG_FILE so
that it contains a path to the selected file.
A system log has the same log levels as a normal log file, with the
exception that instead of FAIL it has the ERROR
level. The threshold level to use can be altered using the
ROBOT_SYSLOG_LEVEL environment variable like shown in the
example below. Possible `unexpected errors and warnings`__ are
written into the system log in addition to the console and the normal
log file.
#!/bin/bash
export ROBOT_SYSLOG_FILE=/tmp/syslog.txt
export ROBOT_SYSLOG_LEVEL=DEBUG
robot --name Syslog_example path/to/tests